In short: This post describes the process of a data collection and gives a bit insight about my text processing algorithm.
A bit of time has elapsed since my last post about twitter data mining. The reason is quite simply… recently I spent most of my free time working on a prototype of my new game. I am quite excited about it and hopefully in the near future I will announce more. Anyway back to Twitter Data Mining.
Recently I have been collecting a polish tweets which are contain the word ‘politics’ or some declination of this this word. Namely : ‘polityka‘, ‘polityce’, ‘polityk’, ‘politycy’, ‘polityke’, ‘polityczna’, ‘politologia’.
To access the Twitter API and get tweets to my computer I use tweepy Python library (http://www.tweepy.org/).
Then collected tweets are processed by my Tweet Processor into pandas data frame. (http://pandas.pydata.org/)
I am improving the Tweet Processor gradually as soon I learn something new about my data set. At this moment Processor is quite simple and can perform really basic things, mainly:
- soft clean of a tweet text – for example removing https links, html tags, user tags etc.
- politics groups name extraction – this maps politics group name declinations into one name,
- stop words removal – this is still in progress and my list of stop words is probably too small right now. I will post someday about my polish language stop words,
- stemming – this is the weakest part of my Text Processor so far. At this moment I map just a few words with its declinations. Polish language is not easy for this task and there is plenty of room to improvement.
As most of this it is just at the begging of development the output data are quite noisy. However instead of trying to make it perfect in first go. I decided to work in a loop:
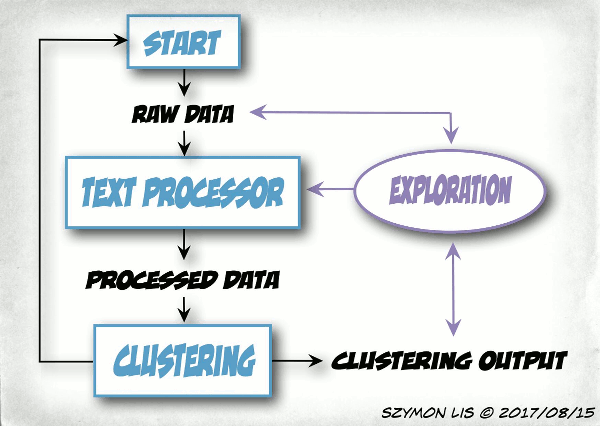
This will allow me to focus on the most important issues and I will learn massively about text analysis.
Next time I will describe more about my clustering approach.
Thank for you time.