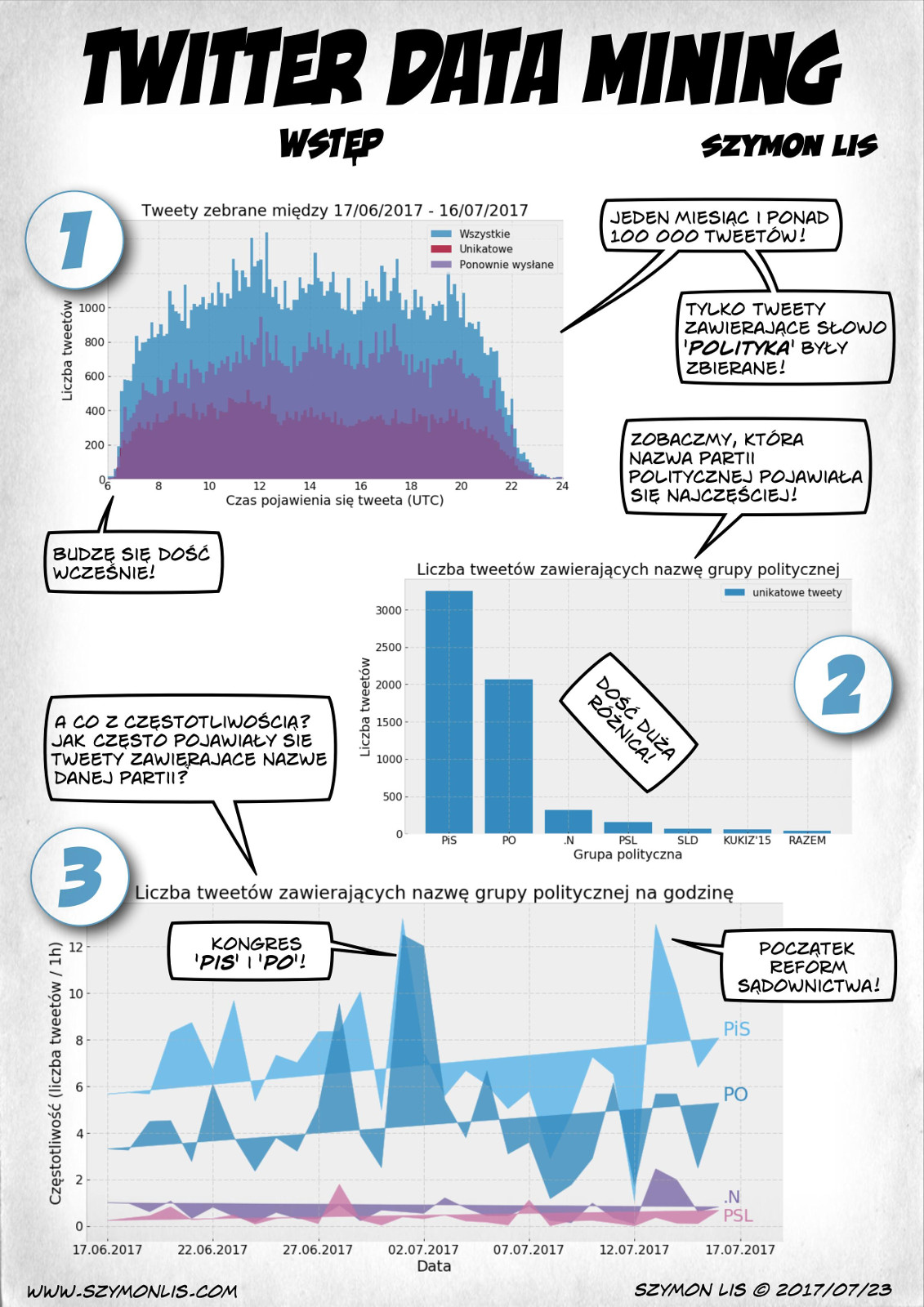
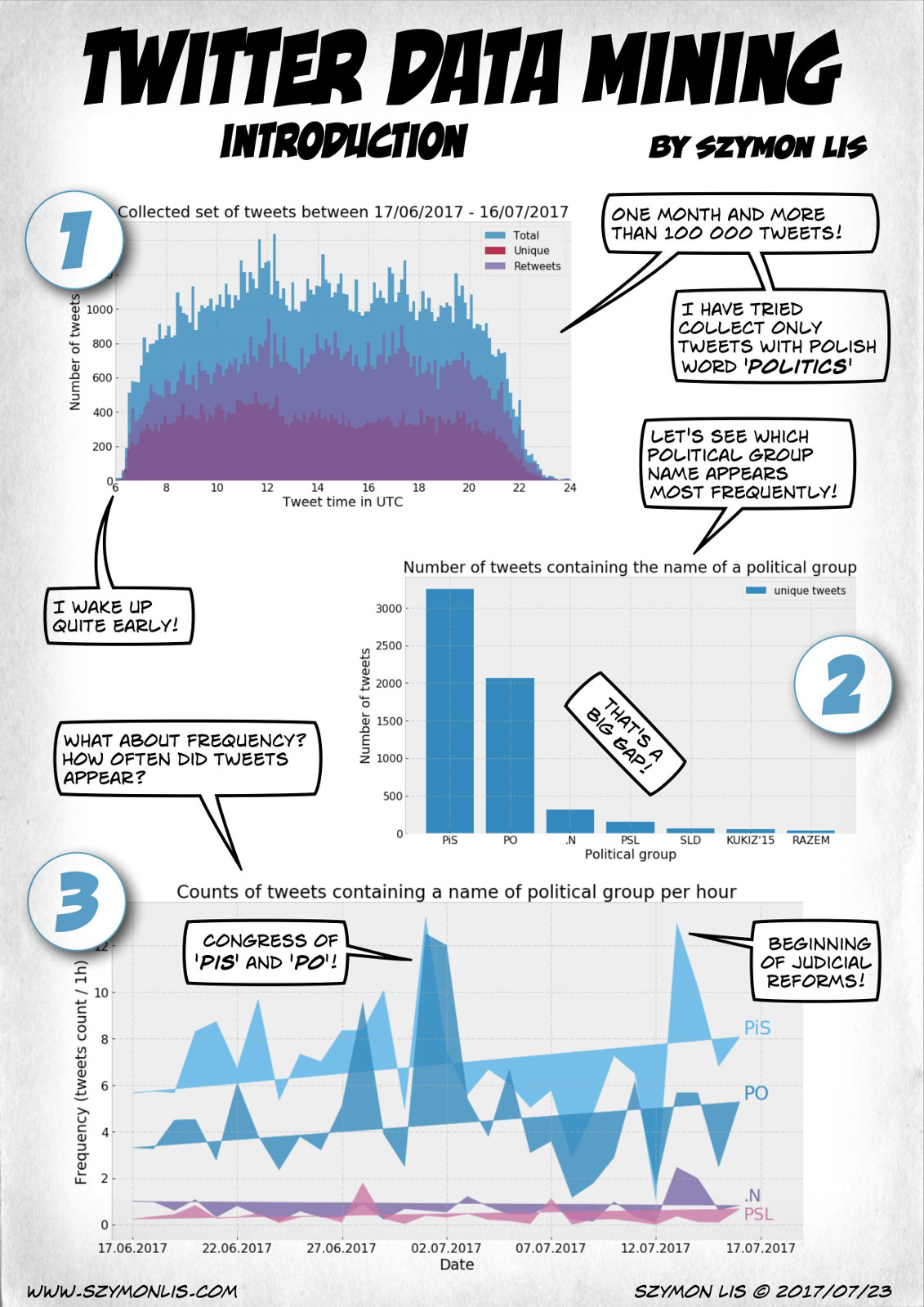
English version and some details below the image keep scrolling!
Lista tagów zawartych w tweetach zebranych w okresie wakacji (Czerwiec – Sierpień) w roku 2017. Tweety były filtrowane słowem ‘polityka’.

Clustering twitter data is not easy. I know that now :). A single tweet is mostly a noise. So at the end you will get a sparse matrix of corpus with density far below 1%. Simply if all corpus contains around 50 000 words (dimensions) but a single tweet has only 10 words (and probably only one or two has some meaning). Lots of noise and sparsity. And finally clustering like k-means put all tweets to one big cluster.
So I decided to change approach and try get something different from collected data.
On my first attempt was to try make words cloud with hashtags.
To do it I used nice python module:
- website: http://amueller.github.io/word_cloud/
- blog: http://peekaboo-vision.blogspot.co.uk/2012/11/a-wordcloud-in-python.html
This image was done on twitter data collected during June, July and August in 2017. The data was filter by polish word ‘polityka’.